人工知能が3D迷路を「視覚」で自力攻略。学習速度と精度が劇的向上
Google DeepMind
Google の AI 開発部門 DeepMind が、最新のアルゴリズムが 3D 迷路を攻略する動画を公開しました。このアルゴリズムはただ迷路を壁にそって移動するのでなく、まだ通っていないと判断した通路を積極的に選んで攻略していく性質を備えます。
Google DeepMind は、AI が(仮想的に)世界を学ぶためにはテレビゲームをプレイするのが最適と考えています。そもそもテレビゲーム自体が仮想体験の塊であり、ひとつのゲームをプレイすればそれをほかの AI に複製するだけで無限に経験を共有できるようになります。
DeepMind は過去、ゲームを課題として学習するアルゴリズム Deep Q-Network(略して "DQN")を開発、ATARI 2600 を使って約50タイトルもの 2D レトロゲームを攻略させ、その得手不得手を検証しました。
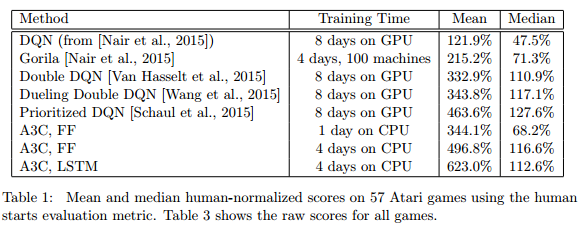
今回のアルゴリズムは DQN を改良したもので、人工ニューラルネットワークの強化学習に非同期メソッドを取り入れたことがポイントです。マルチコアCPUだけで動かした非同期アルゴリズム(asynchronous advantage actor-critic , A3C)は、高性能なTesla K40 GPUで走らせた従来アルゴリズムよりも半分以下の時間で安定してトレーニングでき、ゲームなどテストでの成績も上回ったとしています。
Google DeepMind は、AI が(仮想的に)世界を学ぶためにはテレビゲームをプレイするのが最適と考えています。そもそもテレビゲーム自体が仮想体験の塊であり、ひとつのゲームをプレイすればそれをほかの AI に複製するだけで無限に経験を共有できるようになります。
DeepMind は過去、ゲームを課題として学習するアルゴリズム Deep Q-Network(略して "DQN")を開発、ATARI 2600 を使って約50タイトルもの 2D レトロゲームを攻略させ、その得手不得手を検証しました。
今回のアルゴリズムは DQN を改良したもので、人工ニューラルネットワークの強化学習に非同期メソッドを取り入れたことがポイントです。マルチコアCPUだけで動かした非同期アルゴリズム(asynchronous advantage actor-critic , A3C)は、高性能なTesla K40 GPUで走らせた従来アルゴリズムよりも半分以下の時間で安定してトレーニングでき、ゲームなどテストでの成績も上回ったとしています。
学習に使用する 3D 迷路は1プレイあたりの制限時間があり、プレイするたびにレイアウトがランダムに変化します。またリンゴを拾えば1ポイント、出口を見つければ10ポイントとするルールを設定しました。出口を通過すれば、つぎの迷路へとステージが変わります。

実験ではアルゴリズムに対し、より多くのポイントを獲得するよう課題を与えました。すると最初は1プレイで2ポイントしか獲得できなかったのが、まる3日間ぶっ通しの学習させたところ1プレイあたり約50ポイントを獲得するまでに成長しました。DeepMind は「リンゴを集めるより出口を次々と見つけ出せばポイントが高いということを学んだ」と説明しています。
AI が仮想的な3
次元空間で学習を重ねれば、将来的にその経験を現実(の3次元)空間にも活かせるようになる可能性があります。そしてそれは(Googleも開発中の)自動運転の分野や能動的に行動するロボットなどに応用されていくことになりそうです。
ちなみに DeepMind のアルゴリズムは3D迷路は学んだものの、まだ Doom をはじめとする FPS ゲームには手を付けていません。もし FPS ゲームで仮想的な戦闘体験を繰り返し学習させた場合、超人的な戦闘能力を備える AI を生み出すことも夢ではなさそう。もしそれがリアルの世界、たとえばロシアの戦闘ロボットに搭載されればどうなるのかと考えると...。DeepMind がスカイネット化しないことを祈るばかりです。
ちなみに DeepMind のアルゴリズムは3D迷路は学んだものの、まだ Doom をはじめとする FPS ゲームには手を付けていません。もし FPS ゲームで仮想的な戦闘体験を繰り返し学習させた場合、超人的な戦闘能力を備える AI を生み出すことも夢ではなさそう。もしそれがリアルの世界、たとえばロシアの戦闘ロボットに搭載されればどうなるのかと考えると...。DeepMind がスカイネット化しないことを祈るばかりです。
元論文はこちら
Asynchronous Methods for Deep Reinforcement Learning
(Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap,Tim Harley, David Silver, Koray Kavukcuoglu)
Asynchronous Methods for Deep Reinforcement Learning
(Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap,Tim Harley, David Silver, Koray Kavukcuoglu)